Lecture 7 - Translation, Seq2Seq, Attention
| 작성자 | 작성일 |
|---|---|
| 하유진 | 2022.01.26 |
단원 목표
- 새로운 task 소개: Machine Translation
- 새로운 neural architecture: sequence-to-sequence
- 새로운 neural technique: attention
Section 1: Pre-Neural Machine Translation
Machine Translation
- Machine Translation(MT): 특정 언어(source language)로 쓰여진 문장 x를 다른 언어(target language)의 문장 y로 번역하는 작업
Machine Translation의 역사
- Machine Translation 의 시작 : 1950s
- 1990s~2010s: Statistical Machine Translation
Statistical Machine Translation
- 핵심 아이디어: 데이터로부터 확률적 모델(probabilistic model)을 배우는 것
예를 들어, 주어진 영어 문장 x을 번역한 최상의 한국어 문장 y를 찾는다고 한다면 서로 다른 한국어 번역이 나올 확률은 다음과 같다.
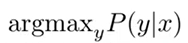
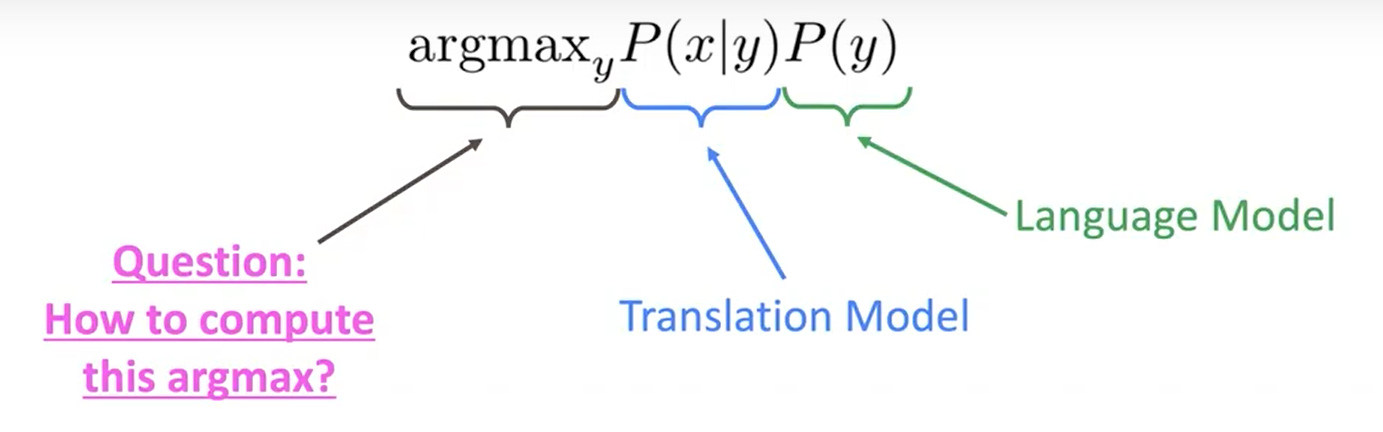
Bayes 규칙을 사용하여 이것을 두 가지 요소로 나눌 수 있다.
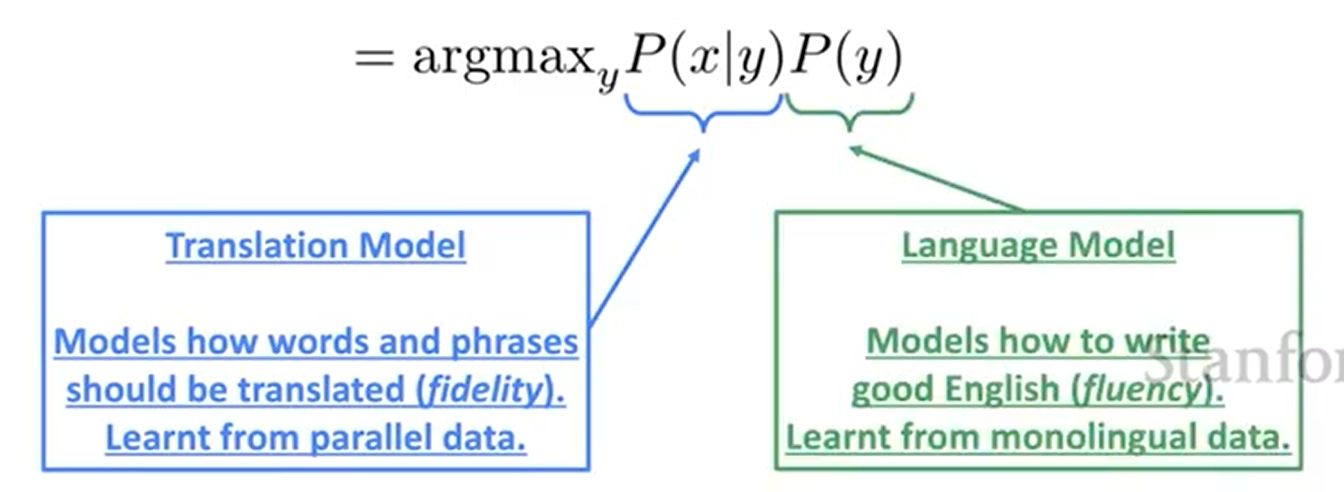
| 어떻게 translation model인 P(x | y)를 학습할 수 있을까? |
→ 많은 양의 병렬 데이터를 이용한다. (예: 인간에 의해 번역된 영어/한국어 문장 쌍)
SMT를 위한 Learning alignment
| 어떻게 병렬 데이터로부터 translation model P(x | y)을 학습하는가? |
| → 한 층 더 분해하기 위해 모델에 잠재 변수 a를 대입한다: P(x, a | y) |
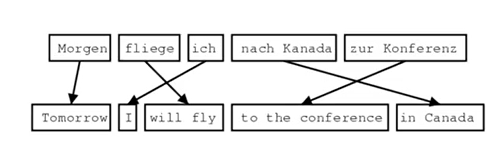
이때 a는 alignment, 즉 source sentence x와 target sentence y 사이의 단어 수준의 관련성이다.
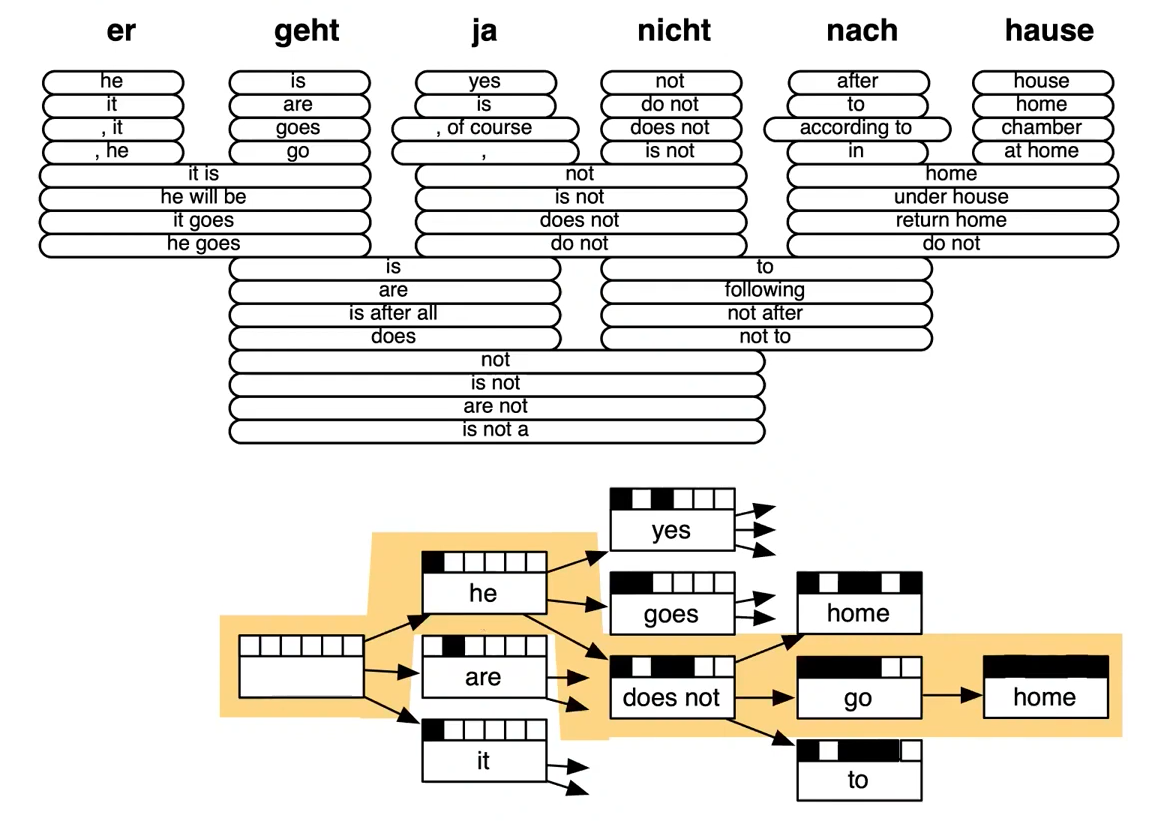
alignment란 무엇인가?
Alignment란 번역된 문장 쌍에서 특정 단어 사이의 관련성을 의미한다.
- 언어 간의 유형학적 차이는 복잡한 alignment를 초래한다.
- 어떤 단어는 대응하는 단어가 없기도 하다.
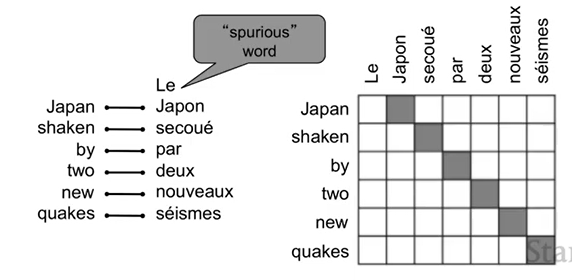
Alignment is complex
- Alignment는 many-to-one 이 될 수 있다.
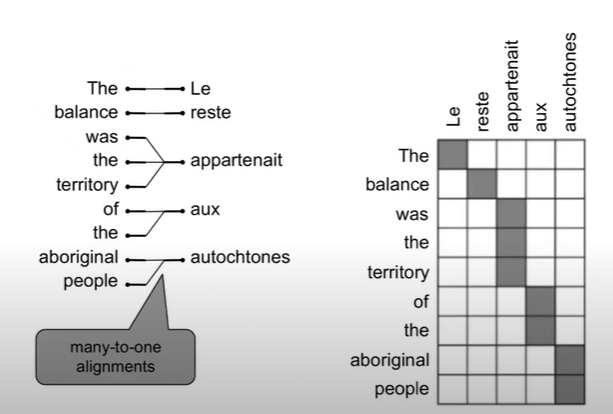
- Alignment는 one-to-many 도 될 수 있다.
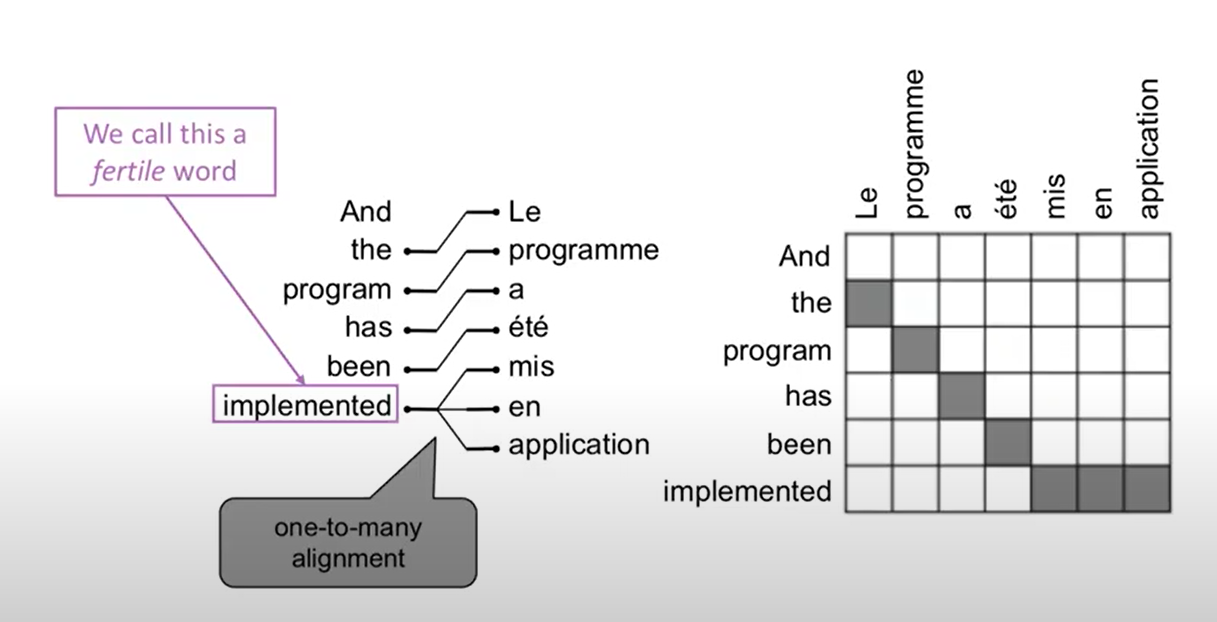
- Alignment는 many-to-many 도 될 수 있다. (phrase-level)
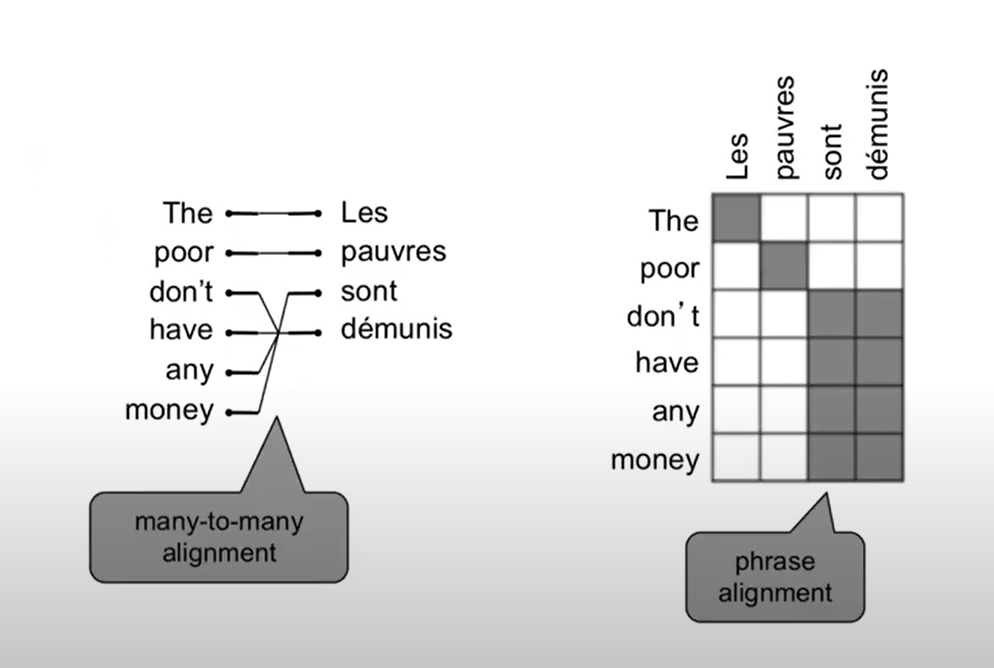
Learning alignment for SMT
-
우리는 P(x, a y)를 다음의 많은 factor의 조합으로 배운다: - 특정 단어 정렬의 확률 (보낸 단어의 위치에 따라서도 다르다)
- 특정 단어가 특정 다산을 가질 확률 (해당 단어의 수)
- 등등.
- Alignment a 는 잠재 변수(latent variables)이다: 이는 데이터에 명시적으로 지정되지 않는다.
- 잠재 변수를 가진 분포의 매개 변수를 학습하기 위해 특수 학습 알고리즘(예를 들면 Expectation-Maximization)을 사용해야 한다.
Decoding for SMT
- 가능한 모든 y를 열거하고 확률을 계산하는 것은 어렵다.
- 따라서 모델에 강력한 독립성 가정(independence assumption)을 적용하고, 최적 솔루션을 위해 동적 프로그래밍을 사용한다. (예를 들면 Viterbi algorithm)
- 이러한 과정을 decoding 이라 한다.
Section 2: Neural Machine Translation
Neural Machine Translation이란?
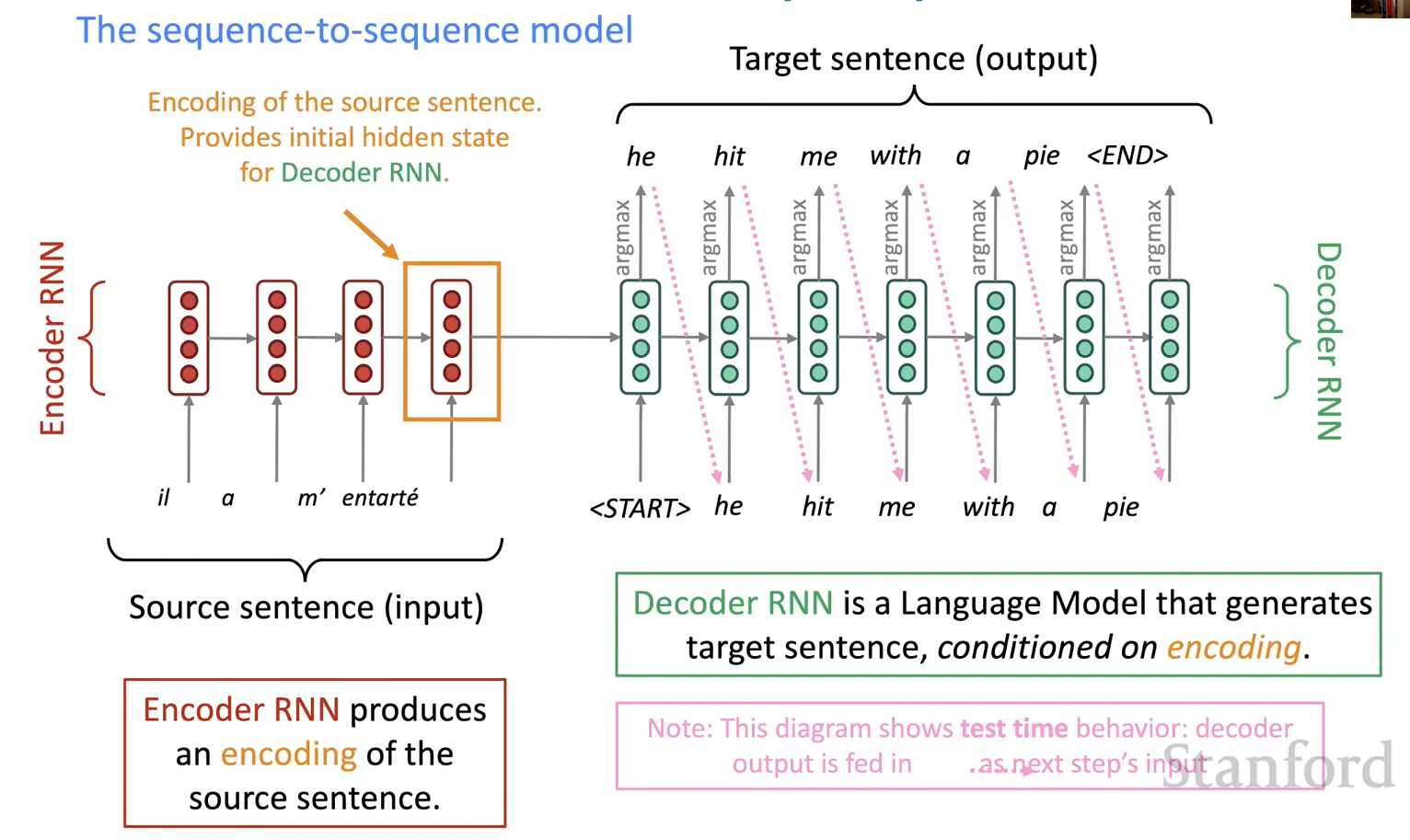
- Neural Machine Translation (NMT)이란 single end-to-end neural network을 사용하여 Machine Translation을 수행하는 방법이다.
- 신경망 구조는 sequence-to-sequence 모델 (일명 seq2seq)라고 하며 두 개의 RNN을 포함한다.
Neural Machine Translation (NMT)
Sequence-to-sequence는 다목적이다
- Sequence-to-sequence는 MT보다 유용하다.
- 많은 NLP 작업은 sequence-to-sequence 로 표현될 수 있다:
- Summarization (long text → short text)
- Dialogue (previous utterances → next utterance)
- Parsing (input text → output parse as sequence)
- Code generation (natural language → Python code)
Neural Machine Translation (NMT)
- sequence-to-sequence 모델은 Conditional Language Model의 한 예이다.
- 디코더가 타겟 문장 y의 다음 단어를 예측하고 있으므로 Language Model이다.
- 그 예측 또한 원본 문장 x에 따라 결정되기 때문에 Conditional이다.\
-
NMT는 P(y x)를 직접적으로 계산한다:

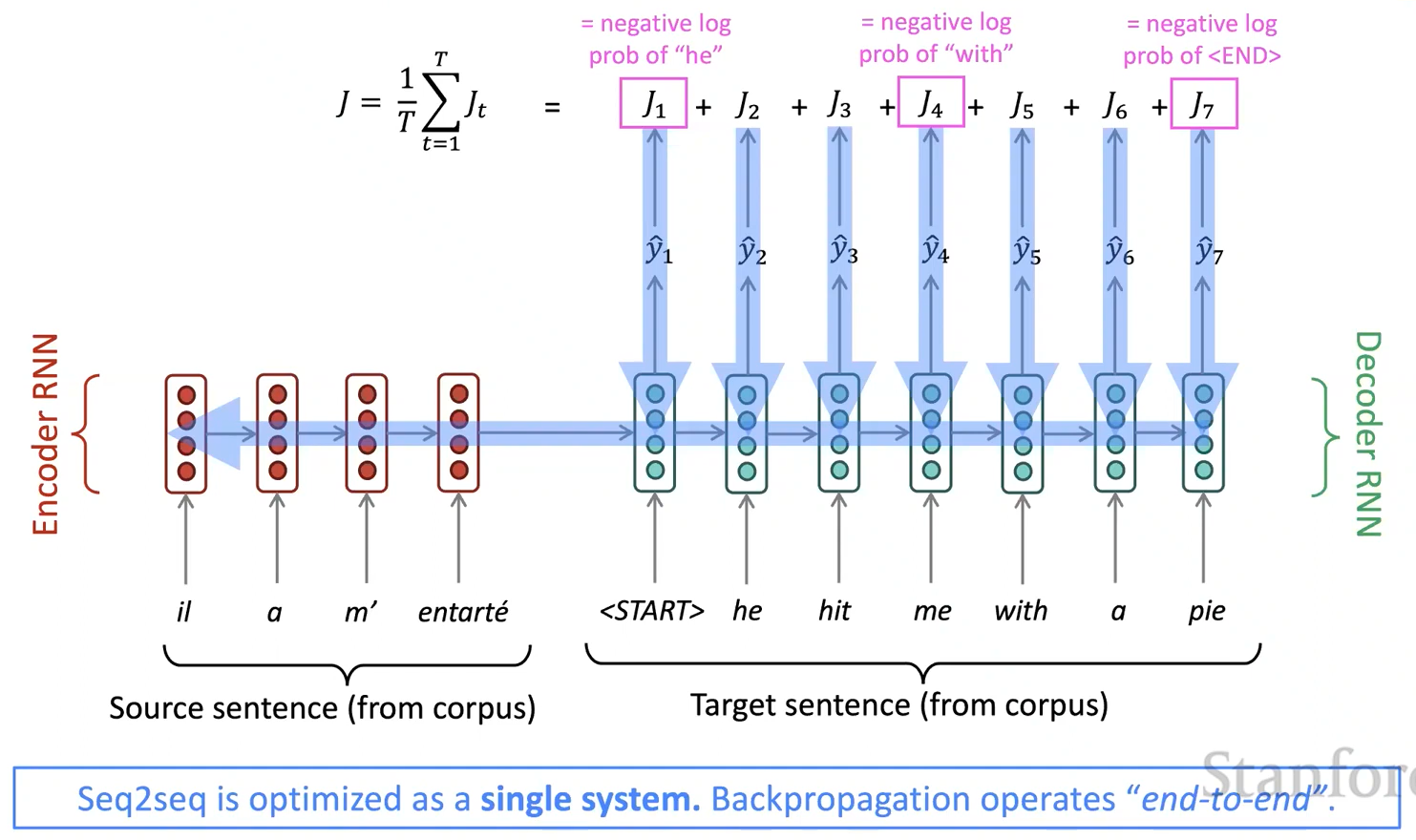
- 어떻게 NMT 시스템을 훈련할까? → 수많은 병렬 말뭉치(**Parallel corpus**)를 이용한다.
Neural Machine Translation system 훈련하기
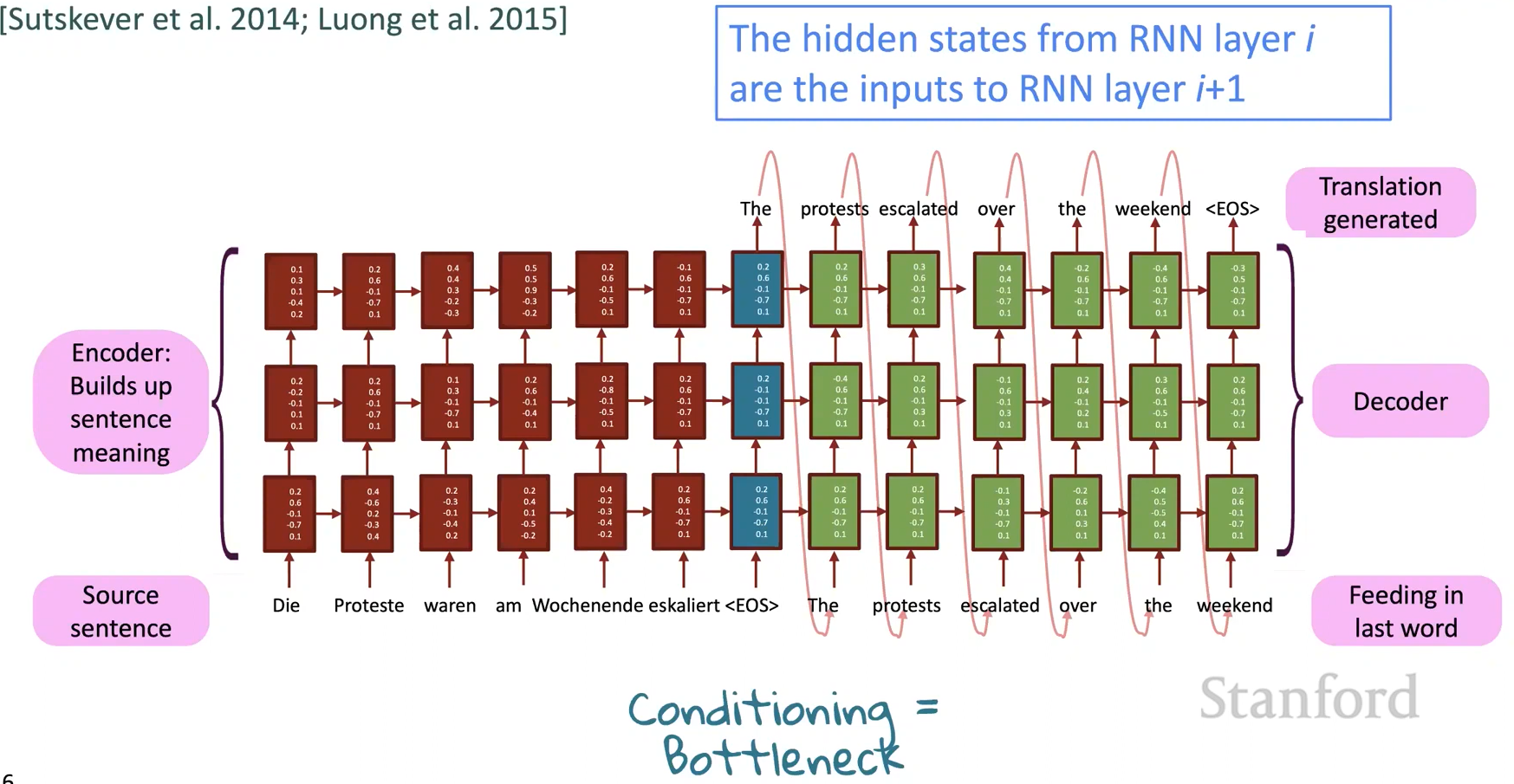
Multi-layer RNNs
- RNN은 이미 1차원에서 “깊이”있다. (많은 시간에 걸쳐서 풀린다.)
- 또한 여러 개의 RNN을 적용하여 다른 차원의 “깊이”를 만들 수 있다. 이것이 multi-layer RNN이다.
- 이를 통해 신경망은 더 복잡한 표현을 계산할 수 있다.
- 낮은 RNN은 닺은 수준의 특징을 계산해야 하고 높은 RNN은 더 높은 수준의 특징을 계산해야 한다.
- Multi-layer RNN은 stacked RNN이라고도 불린다.
Multi-layer deep encoder-decoder machine translation net
Multi-layer RNNs in practice
- 고성능 RNN은 일반적으로 Multi-layer이다.
- Transformer 기반 네트워크는 일반적으로 12개 또는 24개 계층과 같이 더 깊다.
Greedy decoding
- 우리는 디코더의 각 단계에서 argmax를 취함으로써 목표 문장을 생성하는 방법을 보았다.
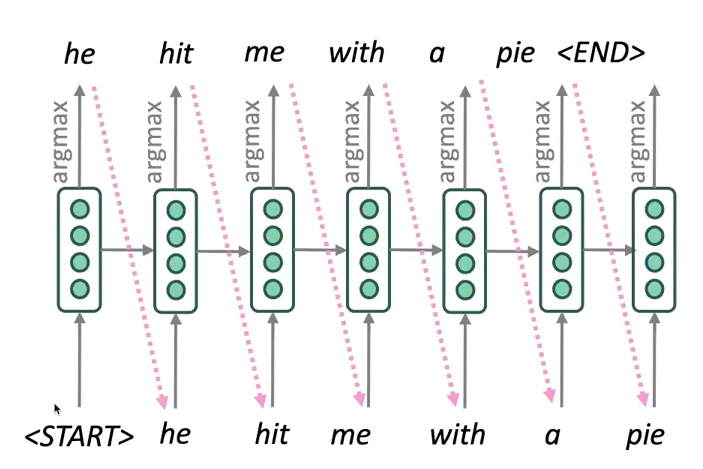
- 이는 각 단계에서 가장 가능성 있는 단어를 취하는 greedy decoding이다.
greedy decoding의 문제점
- greedy decoding은 결정을 되돌릴 수 있는 방법이 없다.
- 이를 어떻게 해결할 수 있을까?
Exhaustive search decoding
-
P(y x)를 최대화하는 길이가 T인 번역문 y를 찾아보자.
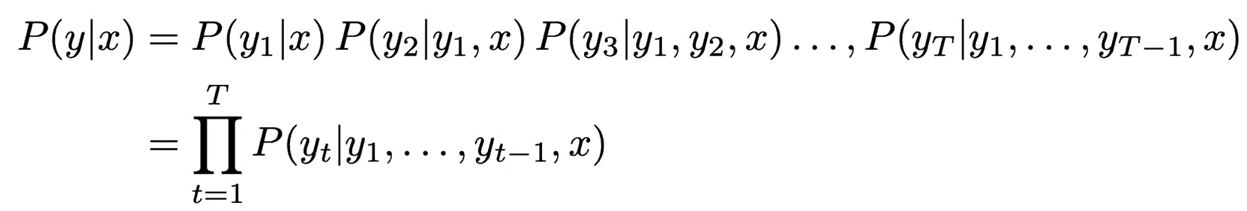
- 우리는 모든 가능한 sequence y를 계산해 볼 수 있다.
- 이는 V가 vocab 사이즈일 때, 디코더의 각 단계 t에서 가능한 부분 변환을 추적하는 것을 의미한다.
Beam search decoding
- 핵심 아이디어: 디코더의 각 단계에서, k개의 가장 가능성이 높은 부분 번역을 추적한다.
- 가설들의 로그 확률은 다음과 같다:
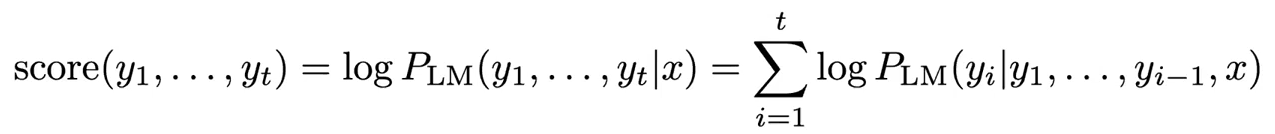
- Beam search가 최적의 솔루션을 찾는다는 것을 보장하지는 않는다.
Beam search decoding 예시
- Beam size = k = 2
- 파란색 숫자들은 로그 확률들
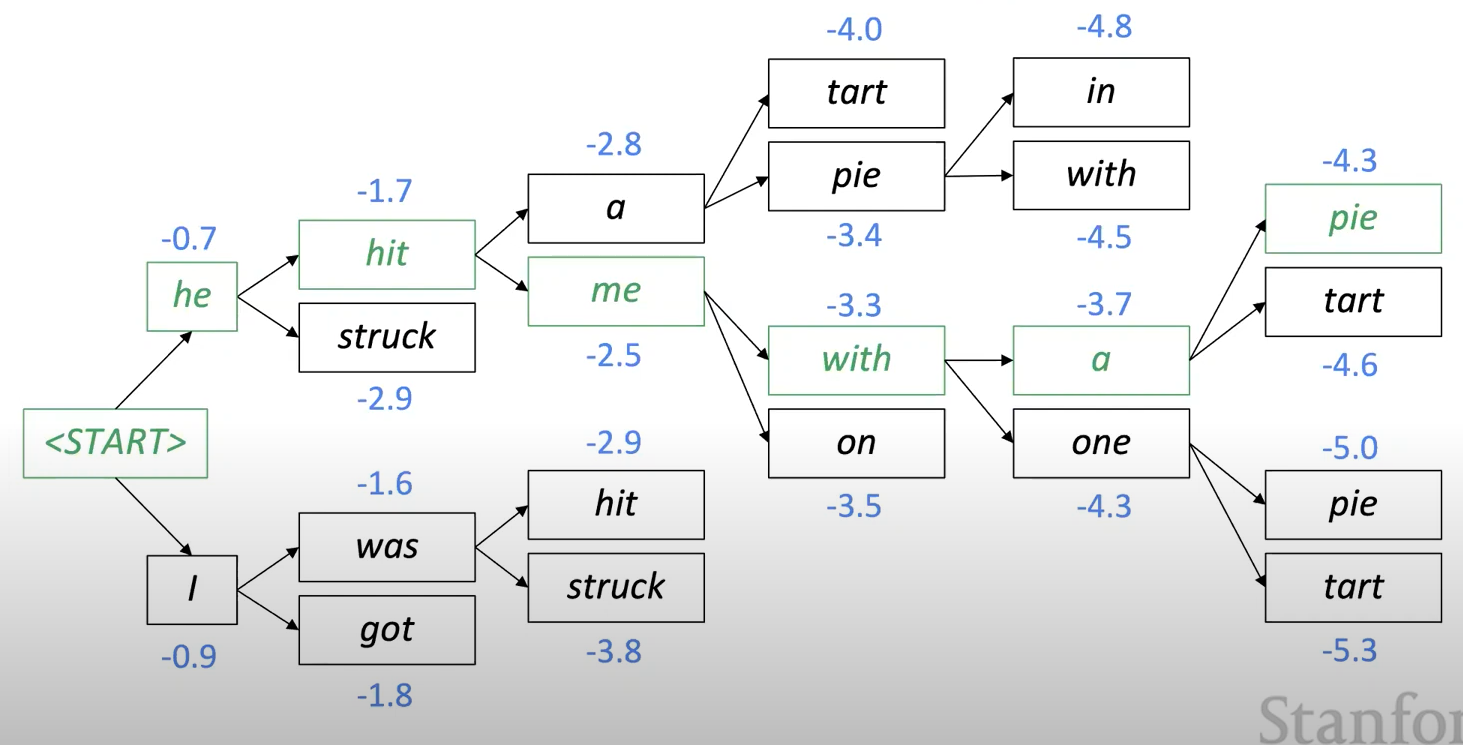
Beam search decoding: 중지 기준
- greedy dicoding 에서는 일반적으로 모델이
토큰을 생성할 때까지 디코딩한다. - 예:
_he hit me with a pie_
- 예:
- Beam search decoding에서 다른 가설은 다른 시간 단계에서
토큰을 생성할 수 있다. - 일반적으로 Beam search는 다음 검색 때까지 계속한다
Beam search decoding: 마무리
- 완성된 가설 목록이 있을 때 어떻게 하면 가장 높은 score를 선택할 수 있을까?
- 리스트의 각 가설들은 score를 갖는다.
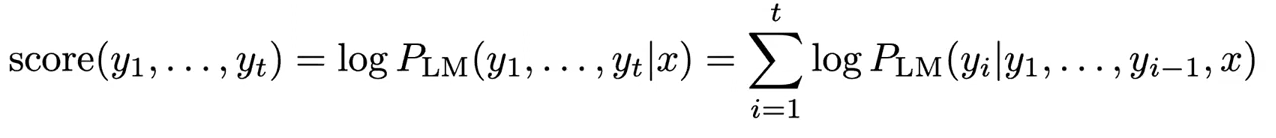
- 문제점: 긴 가설일 수록 score가 낮다.
- 해결방법: 길이로 정규화한다. 이를 통해 맨 위에 있는 항목을 선택한다.
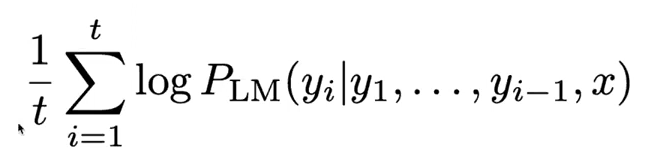
NMT의 장점
SMT와 비교했을 때 NMT는 많은 장점들이 있다.
- 성능이 좋다.
- end-to-end로 최적화 된 single neural network
- 훨씬 적은 인력의 엔지니어 작업 필요
NTM의 단점
SMT에 비해서 NMT는
- 해석이 어려우며
- 통제가 어렵다.